num <- 1:4
num |> map(\(x) x + 1)[[1]]
[1] 2
[[2]]
[1] 3
[[3]]
[1] 4
[[4]]
[1] 5Iteration 2
This session is (mostly) about functional programming:
For coding, we will use r-programming-exercises:
R/iteration-02-01-reading-files.R.For me, here::here() is a truly magical function:
.R files (like today!).Rmd and .qmd filesIf you need to:
here() can make your life much simpler!
👋/Users/ijlyttle/repos/r-programming-exercises/
|-- r-programming-exercises.Rproj
|-- README.md
|-- LICENCE.md
|-- data/
|-- gapminder/
|-- 1952.xlsx
|-- ...
|-- ...
|-- R/
|-- iteration-02-01-reading-files.R
|-- ...Within iteration-02-01-reading-files.R:
here("data/gapminder/1952.xlsx")Works just as well for .Rmd, .qmd files.
🔎
/Users/ijlyttle/repos/r-programming-exercises/
|-- r-programming-exercises.Rproj
|-- README.md
|-- LICENCE.md
|-- data/
|-- gapminder/
|-- 1952.xlsx
|-- ...
|-- ...
|-- R/
|-- iteration-02-01-reading-files.R
|-- ....Rproj file (simplified)🔎
/Users/ijlyttle/repos/r-programming-exercises/
|-- r-programming-exercises.Rproj
|-- README.md
|-- LICENCE.md
|-- data/
|-- gapminder/
|-- 1952.xlsx
|-- ...
|-- ...
|-- R/
|-- iteration-02-01-reading-files.R
|-- ....Rproj
✅
/Users/ijlyttle/repos/r-programming-exercises/
|-- r-programming-exercises.Rproj
|-- README.md
|-- LICENCE.md
|-- data/
|-- gapminder/
|-- 1952.xlsx
|-- ...
|-- ...
|-- R/
|-- iteration-02-01-reading-files.R
|-- ...🚩
/Users/ijlyttle/repos/r-programming-exercises/
|-- r-programming-exercises.Rproj
|-- README.md
|-- LICENCE.md
|-- data/
|-- gapminder/
|-- 1952.xlsx
|-- ...
|-- ...
|-- R/
|-- iteration-02-01-reading-files.R
|-- .../Users/ijlyttle/repos/r-programming-exercises/
🚩
🎯
/Users/ijlyttle/repos/r-programming-exercises/
|-- r-programming-exercises.Rproj
|-- README.md
|-- LICENCE.md
|-- data/
|-- gapminder/
|-- 1952.xlsx
|-- ...
|-- ...
|-- R/
|-- iteration-02-01-reading-files.R
|-- ...here("data/gapminder/1952.xlsx")/Users/ijlyttle/repos/r-programming-exercises/data/gapminder/1952.xlsx
here() returns a string that represents a path.
It makes no guarantee that the path exists.
here() works especially well if you need to rearrange your source (e.g. .R) files.
However, if you move target files (e.g. .xlsx files), you need to modify your calls to here().
The here way:
read_excel(here("data/gapminder/1952.xlsx"))🧐 Where here() can help
read_excel("../data/gapminder/1952.xlsx")🔥 Meme Alert
Do not do this:
setwd("/Users/ijlyttle/repos/r-programming-exercises/data/gapminder")
read_excel("1952.xlsx")Iteration functions in {purrr} can help with repetitive tasks.
Read Excel files from a directory, then combine into a single data-frame.
Here’s our starting code:
data1952 <- read_excel(here("data/gapminder/1952.xlsx"))
data1957 <- read_excel(here("data/gapminder/1957.xlsx"))
data1962 <- read_excel(here("data/gapminder/1952.xlsx"))
data1967 <- read_excel(here("data/gapminder/1967.xlsx"))
data_manual <- bind_rows(data1952, data1957, data1962, data1967)What problems do you see?
(I see two real problems, and one philosophical problem)
Run this example code, discuss with your neighbor.
I see this as a two step problem:
Let’s work together to improve this code to read data:
data <-
paths |>
# read each file from excel, into data frame
# keep only non-null elements
# set list-names as column `year`
# bind into single data-frame
# convert year to number
print()Functional programming has three fundamental paradigms; they act on lists or vectors:
map - do this to each element: purrr::map()
filter - like spaghetti, not coffee: purrr::keep()
reduce - combine into new thing: purrr::reduce()
Each of these takes a function as an argument, to tell the operator what to do.
For coding, we will use r-programming-exercises:
R/iteration-02-02-fundamental-paradigms.R.num <- 1:4
num |> map(\(x) x + 1)map() takes:
num <- 1:4
num |> map(\(x) x + 1)| Input | Result |
|---|---|
| 1 | 2 |
| 2 | |
| 3 | |
| 4 |
num <- 1:4
num |> map(\(x) x + 1)| Input | Result |
|---|---|
| 1 | 2 |
| 2 | 3 |
| 3 | 4 |
| 4 | 5 |
map() always returns a list:
num <- 1:4
num |> map(\(x) x + 1)[[1]]
[1] 2
[[2]]
[1] 3
[[3]]
[1] 4
[[4]]
[1] 5Use an atomic variant to specify type:
num <- 1:4
num |> map_int(\(x) x + 1)[1] 2 3 4 5num <- 1:4
num |> keep(\(x) x %% 2 == 0)Outside {purrr}: known as filter(), but {dplyr} took this name first.
keep() takes:
TRUE or FALSE
num <- 1:4
num |> keep(\(x) x %% 2 == 0)| Input | Evaluation | Result |
|---|---|---|
| 1 | FALSE |
|
| 2 | TRUE |
2 |
| 3 | ||
| 4 |
num <- 1:4
num |> keep(\(x) x %% 2 == 0)| Input | Evaluation | Result |
|---|---|---|
| 1 | FALSE |
|
| 2 | TRUE |
2 |
| 3 | FALSE |
|
| 4 | TRUE |
4 |
num <- 1:4
num |> reduce(\(acc, x) acc + x)reduce() takes:
num <- 1:4
num |> reduce(\(acc, x) acc + x)| Input | Result |
|---|---|
| 1 | 1 |
| 2 | |
| 3 | |
| 4 |
num <- 1:4
num |> reduce(\(acc, x) acc + x)| Input | Result |
|---|---|
| 1 | |
| 2 | 3 |
| 3 | |
| 4 |
num <- 1:4
num |> reduce(\(acc, x) acc + x)| Input | Result |
|---|---|
| 1 | |
| 2 | |
| 3 | |
| 4 | 10 |
num <- 1:4
num |> reduce(\(acc, x) acc + x, .init = 1)| Input | Result |
|---|---|
| 1 | |
| 2 | |
| 3 | |
| 4 | 11 |
num <- 1:4
num |> reduce(sum, .init = 1)| Input | Result |
|---|---|
| 1 | |
| 2 | |
| 3 | |
| 4 | 11 |
num <- c(1, 2, 3, NA, 4)
num |> reduce(sum)[1] NAThe default behavior for sum() is not to remove NA values.
To change the behavior, use an anonymous function:
num |> reduce(\(acc, x) sum(acc, x, na.rm = TRUE))[1] 10No longer recommended
num |> reduce(sum, na.rm = TRUE)Using an anonymous function will:
Some useful variants, can mix and match:
map_lgl() , map_int(), map_dbl(), map_chr()
walk(): like map(), but called for side-effectimap(), lmap(): use index or list-name as argumentmap2(), pmap(): apply over sets of inputsAdverbs modify verbs (functions):
possibly(), quietly(), slowly(), insistently(), safely()
negate(): return the negative of a predicatecompose(): put two functions togetherpartial(): pre-fill some arguments of a functionIf we have a failure, we may not want to stop everything.
For coding, we will use r-programming-exercises:
R/iteration-02-03-adverbs.R.Function operators:
possibly_read_csv("not/a/file.csv")Error: 'not/a/file.csv' does not exist in current working directory ('/home/runner/work/r-programming/r-programming').NULLpossibly_read_csv(I("a, b\n 1, 2"), col_types = "dd")# A tibble: 1 × 2
a b
<dbl> <dbl>
1 1 2In the r-programming-exercises repository:
data/gapminder_party/
Create a new function:
possibly_read_excel <- possibly() # we do the restUse this function in your script.
list_rbind()
Re-implement list_rbind() using functional-programming techniques:
Let’s run this, uncommenting one line at a time.
NULL values, purrr::keep()
purrr::imap()
purrr::reduce()
We have seen functions as arguments in:
map(), keep(), reduce(): tells them what to dopossibly(): tells what behavior to modifyUsing functions, themselves, as arguments takes a little getting used-to.
Once you wrap your mind around it, it’s like seeing in more dimensions.
For coding, we will use r-programming-exercises:
R/iteration-02-04-functions-as-arguments.R.library("tidyverse")
library("palmerpenguins")
library("conflicted")
conflicts_prefer(palmerpenguins::penguins)
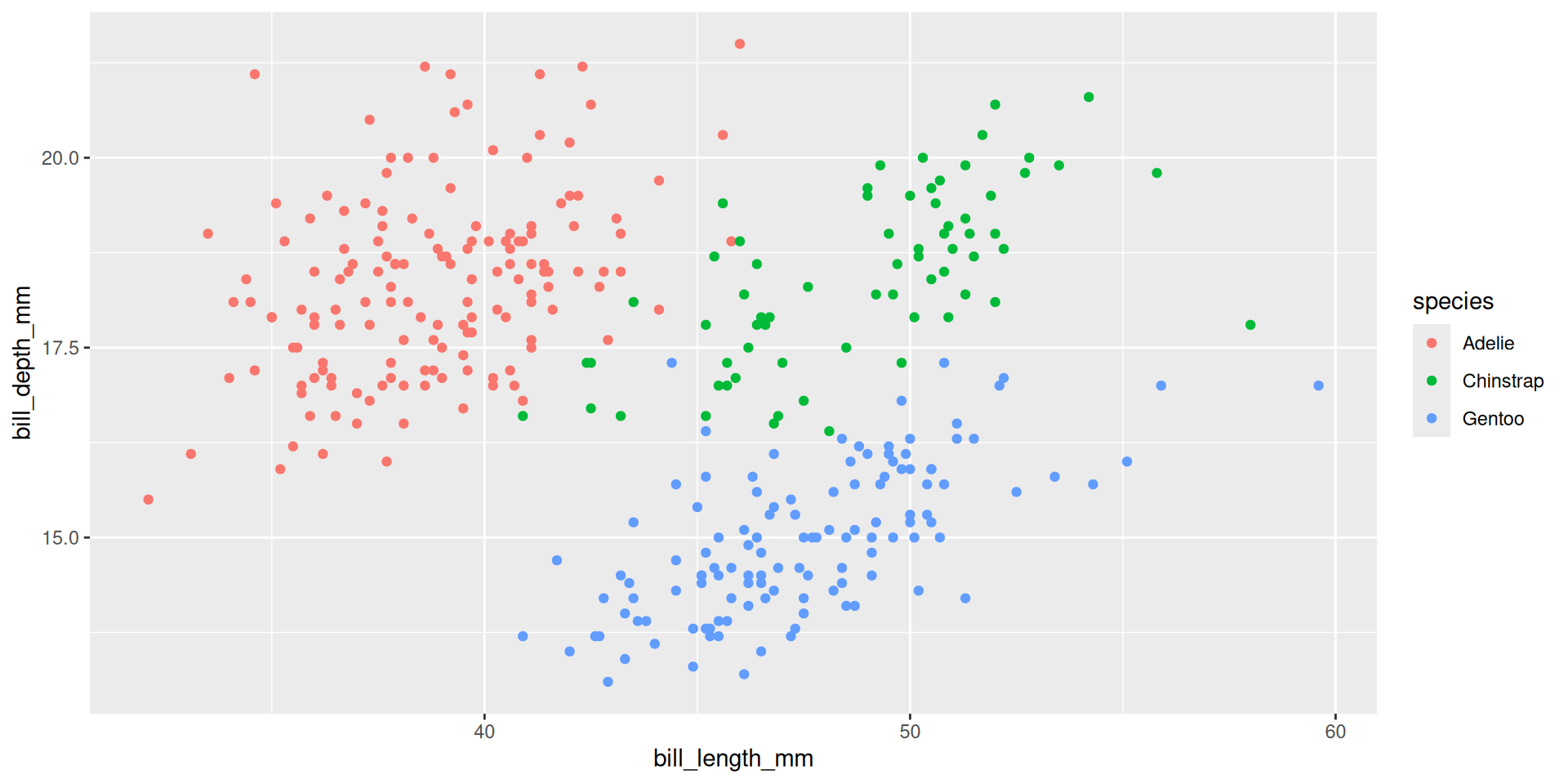
ggplot(penguins, aes(x = bill_length_mm, y = bill_depth_mm, color = species)) +
geom_point()What if we want lower-case names for the species?
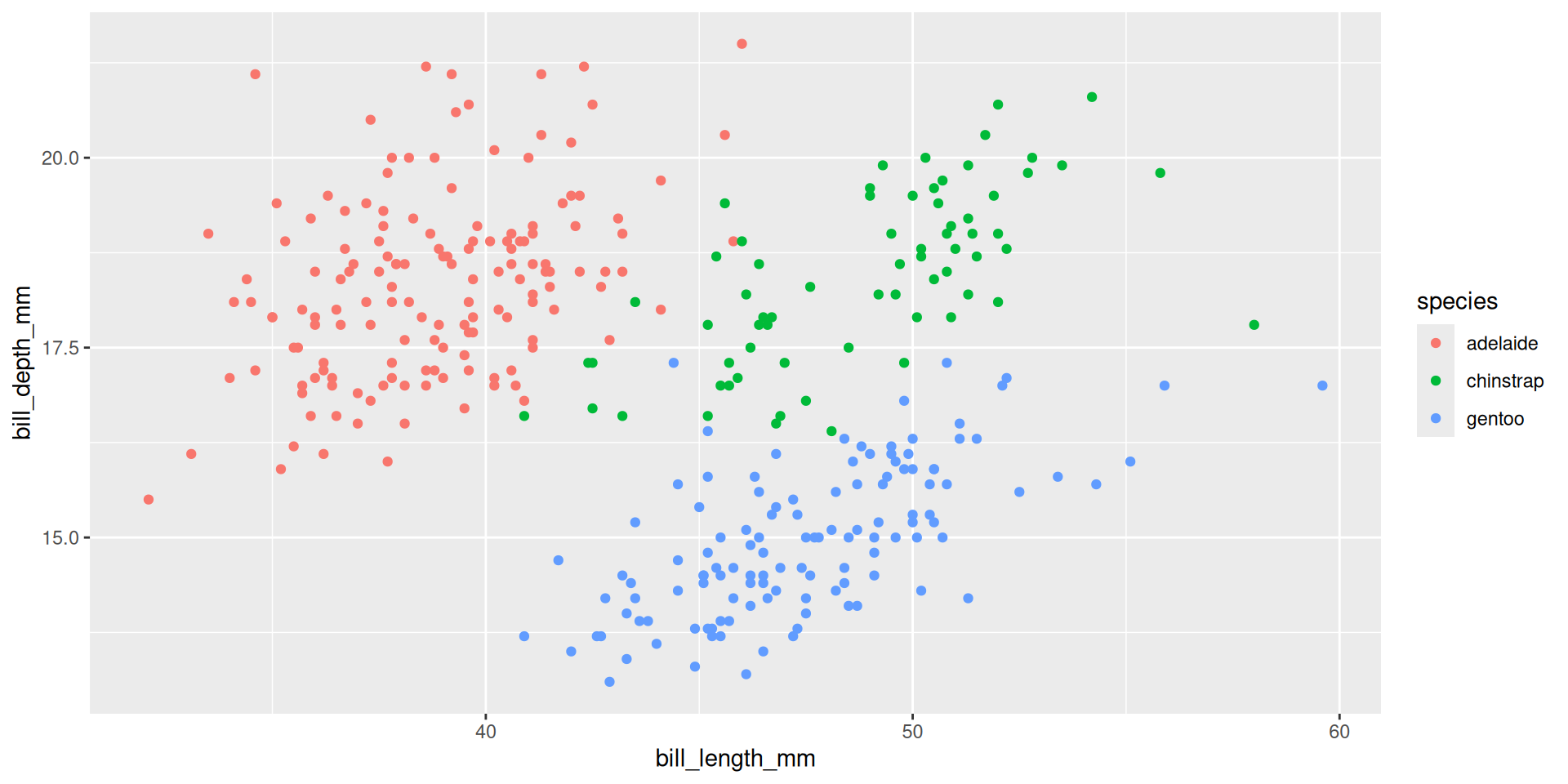
ggplot(penguins, aes(x = bill_length_mm, y = bill_depth_mm, color = species)) +
geom_point() +
scale_color_discrete(labels = c("adelaide", "chinstrap", "gentoo"))We can do it manually, but what if we get a dataset with more species?
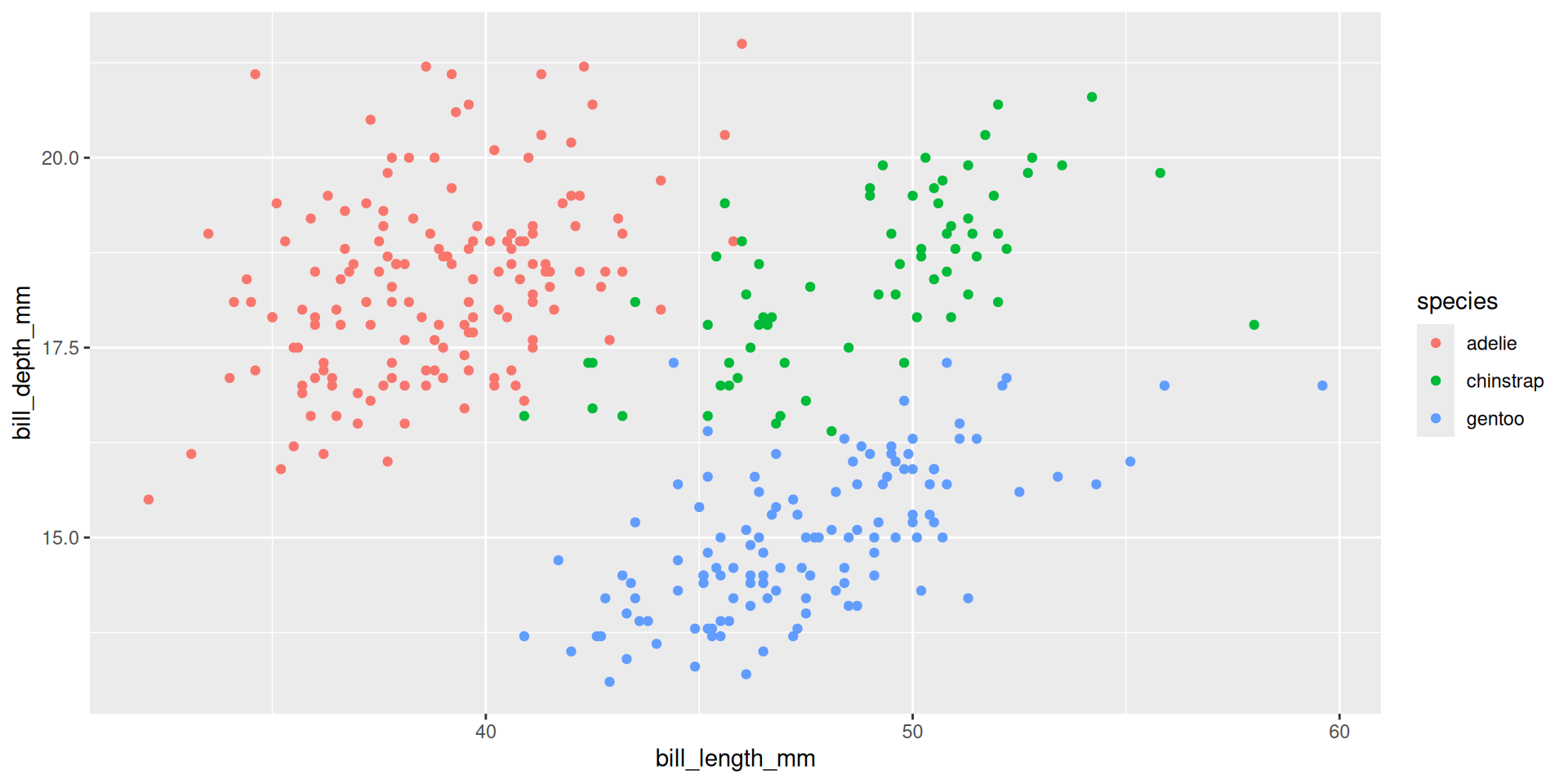
ggplot(penguins, aes(x = bill_length_mm, y = bill_depth_mm, color = species)) +
geom_point() +
scale_color_discrete(labels = tolower) # tolower is a functionLook at ?discrete_scale: labels can take a function.
Function operators (adverbs) return modified functions 🤯
Function factories return functions “out of thin air” 🤯🤯
{scales}, used for {ggplot2} is full of these function factories!
## use scales:: notation, vs. library(), to help autocomplete
percent_labeller <- scales::label_percent(accuracy = 1)# percent_labeller is a function
percent_labeller(c(0, 0.01, 0.1, 1))[1] "0%" "1%" "10%" "100%"Play around with:
accuracypercent_labeller
Add scale_y_continuous() to this plot, to use a percentage-labeller.
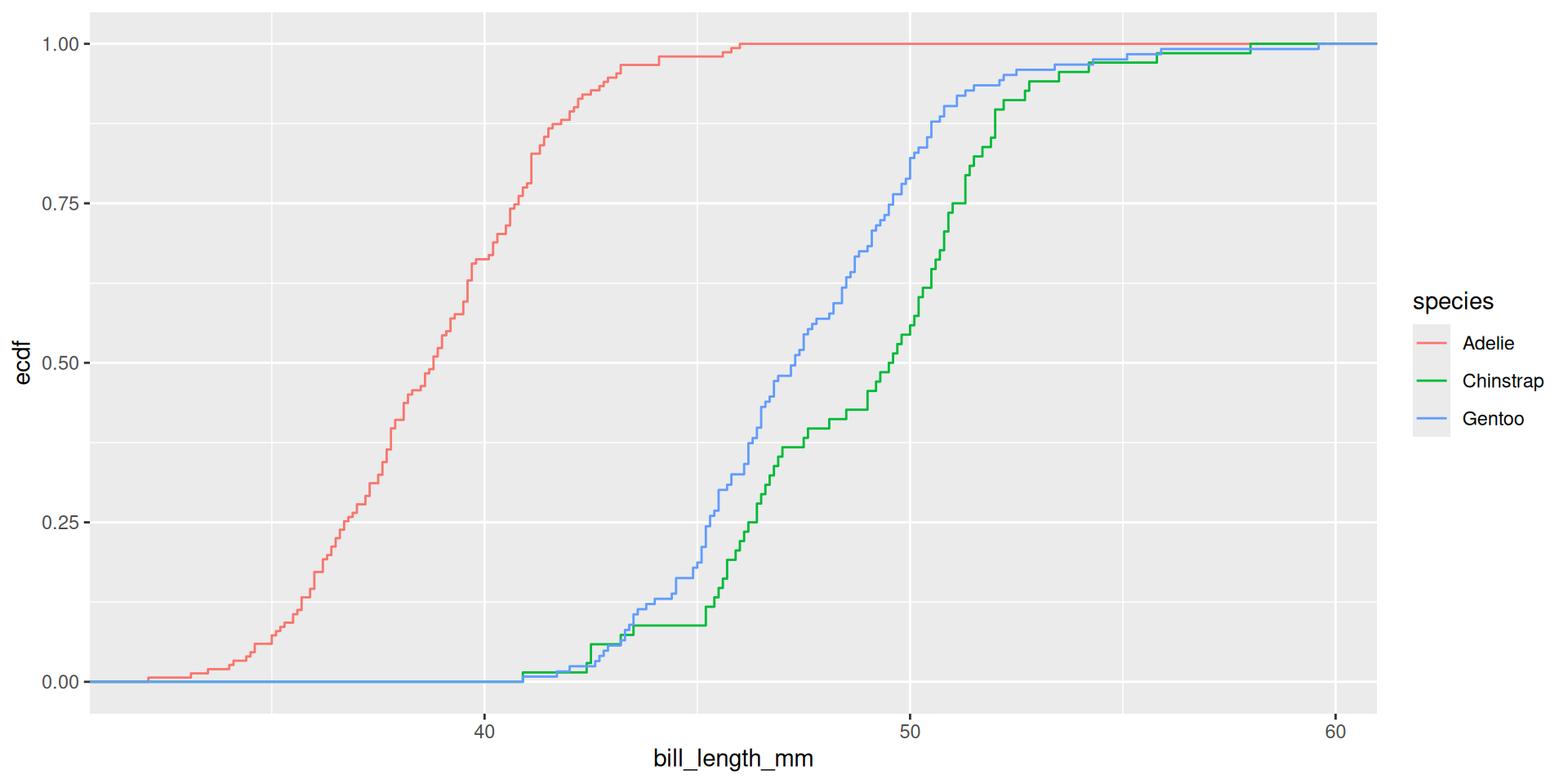
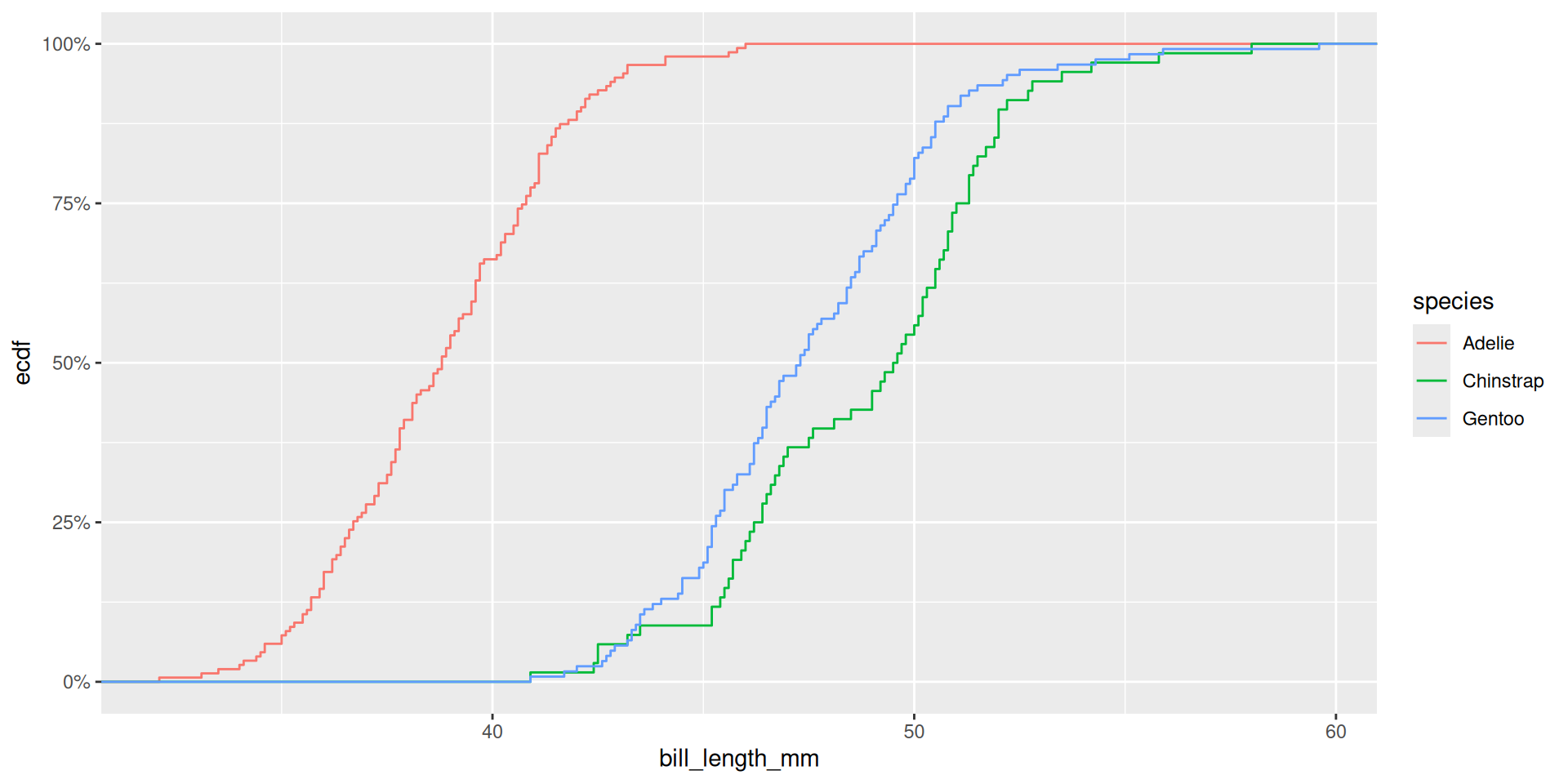
ggplot(penguins, aes(x = bill_length_mm, color = species)) +
stat_ecdf() +
scale_y_continuous(labels = scales::label_percent(accuracy = 1))To me, this is a cleaner solution than mutating the data from decimal to percent.
Let’s say you wanted to double this:
original <- 1:4Of course, base R has the ultimate declarative approach:
2 * original[1] 2 4 6 8ui.dev has a very accessible article on the two approaches.
Three fundamental paradigms in functional programming
Given a list and a function:
keep(): make a new list, subset of old listmap(): make a new list, operating on each elementreduce(): make a new “thing”For coding, we will use r-programming-exercises:
R/iteration-02-05-dpurrr.R.We can use purrr::keep(), purrr::map(), purrr::reduce() to “implement”:
I claim it’s possible, I don’t claim it’s a good idea.
library("conflicted")
library("palmerpenguins")
library("dplyr")
library("purrr")
conflicts_prefer(palmerpenguins::penguins)
# simplify penguins (Sorry Allison!)
penguins_local <-
penguins |>
mutate(across(where(is.factor), as.character)) |> # use strings, not factors
select(species, island, body_mass_g, sex) |> # fewer columns
print()# A tibble: 344 × 4
species island body_mass_g sex
<chr> <chr> <int> <chr>
1 Adelie Torgersen 3750 male
2 Adelie Torgersen 3800 female
3 Adelie Torgersen 3250 female
4 Adelie Torgersen NA <NA>
5 Adelie Torgersen 3450 female
6 Adelie Torgersen 3650 male
7 Adelie Torgersen 3625 female
8 Adelie Torgersen 4675 male
9 Adelie Torgersen 3475 <NA>
10 Adelie Torgersen 4250 <NA>
# ℹ 334 more rowscolumn-based: named list of column vectors
row-based: collection of rows, each a named list
We have a couple of helper functions to convert to:
Data frames: column-based
#' @param .d unnamed list of named lists, i.e. transposed data frame
#'
#' @return tibble
dpurrr_to_tibble <- function(.d) {
.d |>
purrr::list_transpose() |>
tibble::as_tibble()
} Lists of lists: row-based
#' @param .data data frame or tibble
#'
#' @return unnamed list of named lists, i.e. transposed data frame
dpurrr_to_list <- function(.data) {
.data |>
as.list() |>
purrr::list_transpose(simplify = FALSE)
}List of 2
$ :List of 4
..$ species : chr "Adelie"
..$ island : chr "Torgersen"
..$ body_mass_g: int 3750
..$ sex : chr "male"
$ :List of 4
..$ species : chr "Adelie"
..$ island : chr "Torgersen"
..$ body_mass_g: int 3800
..$ sex : chr "female"Comment and change lines as you see fit.
Predicate function acts on each “row”, d, which is a list:
List of 4
$ species : chr "Adelie"
$ island : chr "Torgersen"
$ body_mass_g: int 3750
$ sex : chr "male"List of 4
$ species : chr "Adelie"
$ island : chr "Torgersen"
$ body_mass_g: int 3800
$ sex : chr "female"List of 4
$ species : chr "Adelie"
$ island : chr "Torgersen"
$ body_mass_g: int 3250
$ sex : chr "female"Predicate function acts on each “row”, d, which is a list:
List of 4
$ species : chr "Adelie"
$ island : chr "Torgersen"
$ body_mass_g: int 3750
$ sex : chr "male"List of 4
$ species : chr "Adelie"
$ island : chr "Torgersen"
$ body_mass_g: int 3800
$ sex : chr "female"List of 4
$ species : chr "Adelie"
$ island : chr "Torgersen"
$ body_mass_g: int 3250
$ sex : chr "female"Predicate function acts on each “row”, d, which is a list:
List of 4
$ species : chr "Adelie"
$ island : chr "Torgersen"
$ body_mass_g: int 3750
$ sex : chr "male"List of 4
$ species : chr "Adelie"
$ island : chr "Torgersen"
$ body_mass_g: int 3800
$ sex : chr "female"List of 4
$ species : chr "Adelie"
$ island : chr "Torgersen"
$ body_mass_g: int 3250
$ sex : chr "female"Re-assembled into a tibble:
# A tibble: 165 × 4
species island body_mass_g sex
<chr> <chr> <int> <chr>
1 Adelie Torgersen 3800 female
2 Adelie Torgersen 3250 female
3 Adelie Torgersen 3450 female
4 Adelie Torgersen 3625 female
5 Adelie Torgersen 3200 female
6 Adelie Torgersen 3700 female
7 Adelie Torgersen 3450 female
8 Adelie Torgersen 3325 female
9 Adelie Biscoe 3400 female
10 Adelie Biscoe 3800 female
# ℹ 155 more rows#' @param .d unnamed list of named lists, i.e. transposed data frame
#' @param mapper function applied to each member of `.d`
#'
#' @return unnamed list of named lists, i.e. transposed data frame
dpurrr_mutate <- function(.d, mapper) {
# modifyList() used to keep current elements
.d |> purrr::map(\(d) modifyList(d, mapper(d)))
}This version of mutate operates on every “row”, modifying its list.
# A tibble: 344 × 4
species island body_mass_g sex
<chr> <chr> <int> <chr>
1 Adelie Torgersen 3750 male
2 Adelie Torgersen 3800 female
3 Adelie Torgersen 3250 female
4 Adelie Torgersen NA <NA>
5 Adelie Torgersen 3450 female
6 Adelie Torgersen 3650 male
7 Adelie Torgersen 3625 female
8 Adelie Torgersen 4675 male
9 Adelie Torgersen 3475 <NA>
10 Adelie Torgersen 4250 <NA>
# ℹ 334 more rowsList of 4
$ species : chr "Adelie"
$ island : chr "Torgersen"
$ body_mass_g: int 3750
$ sex : chr "male"List of 4
$ species : chr "Adelie"
$ island : chr "Torgersen"
$ body_mass_g: int 3800
$ sex : chr "female"List of 4
$ species : chr "Adelie"
$ island : chr "Torgersen"
$ body_mass_g: int 3250
$ sex : chr "female"List of 5
$ species : chr "Adelie"
$ island : chr "Torgersen"
$ body_mass_g : int 3750
$ sex : chr "male"
$ body_mass_kg: num 3.75List of 5
$ species : chr "Adelie"
$ island : chr "Torgersen"
$ body_mass_g : int 3800
$ sex : chr "female"
$ body_mass_kg: num 3.8List of 5
$ species : chr "Adelie"
$ island : chr "Torgersen"
$ body_mass_g : int 3250
$ sex : chr "female"
$ body_mass_kg: num 3.25# A tibble: 344 × 5
species island body_mass_g sex body_mass_kg
<chr> <chr> <int> <chr> <dbl>
1 Adelie Torgersen 3750 male 3.75
2 Adelie Torgersen 3800 female 3.8
3 Adelie Torgersen 3250 female 3.25
4 Adelie Torgersen NA <NA> NA
5 Adelie Torgersen 3450 female 3.45
6 Adelie Torgersen 3650 male 3.65
7 Adelie Torgersen 3625 female 3.62
8 Adelie Torgersen 4675 male 4.68
9 Adelie Torgersen 3475 <NA> 3.48
10 Adelie Torgersen 4250 <NA> 4.25
# ℹ 334 more rows#' @param .d unnamed list of named lists, i.e. transposed data frame
#' @param reducer function applied accumulator and to each member of `.d`
#' @param .init initial value of accumulator, if empty: first element of `.d`
#' @param ... other arguments passed to `purrr::reduce()`
#'
#' @return unnamed list of named lists, i.e. transposed data frame
dpurrr_summarise <- function(.d, reducer, .init, ...) {
# wrap result in a list, to return a transposed data frame
.d |> purrr::reduce(reducer, .init = .init, ...) |> list()
}Takes a transposed data frame, returns a transposed data frame with a single “row”.
# A tibble: 344 × 4
species island body_mass_g sex
<chr> <chr> <int> <chr>
1 Adelie Torgersen 3750 male
2 Adelie Torgersen 3800 female
3 Adelie Torgersen 3250 female
4 Adelie Torgersen NA <NA>
5 Adelie Torgersen 3450 female
6 Adelie Torgersen 3650 male
7 Adelie Torgersen 3625 female
8 Adelie Torgersen 4675 male
9 Adelie Torgersen 3475 <NA>
10 Adelie Torgersen 4250 <NA>
# ℹ 334 more rowsList of 4
$ species : chr "Adelie"
$ island : chr "Torgersen"
$ body_mass_g: int 3750
$ sex : chr "male"List of 4
$ species : chr "Adelie"
$ island : chr "Torgersen"
$ body_mass_g: int 3800
$ sex : chr "female"List of 4
$ species : chr "Adelie"
$ island : chr "Torgersen"
$ body_mass_g: int 3250
$ sex : chr "female"List of 2
$ body_mass_g_min: int 2700
$ body_mass_g_max: int 6300# A tibble: 1 × 2
body_mass_g_min body_mass_g_max
<int> <int>
1 2700 6300We need a couple more functions to split and combine, also for our reducer:
#' @param .d unnamed list of named lists, i.e. transposed data frame
#' @param name string, name of variable on which to split
#'
#' @return named list of transposed data frames, names: values of split variable
dpurrr_split <- function(.d, name) {
# uses purrr::map(), purrr::set_names(), purrr::keep()
}#' @param .nd named list of transposed data frames
#' @param name string, name of variable to put into combined list
#'
#' @return transposed data frame
dpurrr_combine <- function(.nd, name) {
# uses purrr::imap(), purrr::reduce()
}# A tibble: 344 × 4
species island body_mass_g sex
<chr> <chr> <int> <chr>
1 Adelie Torgersen 3750 male
2 Adelie Torgersen 3800 female
3 Adelie Torgersen 3250 female
4 Adelie Torgersen NA <NA>
5 Adelie Torgersen 3450 female
6 Adelie Torgersen 3650 male
7 Adelie Torgersen 3625 female
8 Adelie Torgersen 4675 male
9 Adelie Torgersen 3475 <NA>
10 Adelie Torgersen 4250 <NA>
# ℹ 334 more rows List of 4
$ species : chr "Adelie"
$ island : chr "Torgersen"
$ body_mass_g: int 3750
$ sex : chr "male" List of 4
$ species : chr "Adelie"
$ island : chr "Torgersen"
$ body_mass_g: int 3800
$ sex : chr "female" List of 4
$ species : chr "Gentoo"
$ island : chr "Biscoe"
$ body_mass_g: int 4500
$ sex : chr "female" List of 4
$ species : chr "Gentoo"
$ island : chr "Biscoe"
$ body_mass_g: int 5700
$ sex : chr "male" List of 4
$ species : chr "Chinstrap"
$ island : chr "Dream"
$ body_mass_g: int 3500
$ sex : chr "female" List of 4
$ species : chr "Chinstrap"
$ island : chr "Dream"
$ body_mass_g: int 3900
$ sex : chr "male"$Adelie List of 4
$ species : chr "Adelie"
$ island : chr "Torgersen"
$ body_mass_g: int 3750
$ sex : chr "male" List of 4
$ species : chr "Adelie"
$ island : chr "Torgersen"
$ body_mass_g: int 3800
$ sex : chr "female"$Gentoo List of 4
$ species : chr "Gentoo"
$ island : chr "Biscoe"
$ body_mass_g: int 4500
$ sex : chr "female" List of 4
$ species : chr "Gentoo"
$ island : chr "Biscoe"
$ body_mass_g: int 5700
$ sex : chr "male"$Chinstrap List of 4
$ species : chr "Chinstrap"
$ island : chr "Dream"
$ body_mass_g: int 3500
$ sex : chr "female" List of 4
$ species : chr "Chinstrap"
$ island : chr "Dream"
$ body_mass_g: int 3900
$ sex : chr "male"$Adelie List of 2
$ body_mass_g_min: int 2850
$ body_mass_g_max: int 4775$Gentoo List of 2
$ body_mass_g_min: int 3950
$ body_mass_g_max: int 6300$Chinstrap List of 2
$ body_mass_g_min: int 2700
$ body_mass_g_max: int 4800$Adelie List of 3
$ body_mass_g_min: int 2850
$ body_mass_g_max: int 4775
$ species : chr "Adelie"$Gentoo List of 3
$ body_mass_g_min: int 3950
$ body_mass_g_max: int 6300
$ species : chr "Gentoo"$Chinstrap List of 3
$ body_mass_g_min: int 2700
$ body_mass_g_max: int 4800
$ species : chr "Chinstrap" List of 3
$ body_mass_g_min: int 2850
$ body_mass_g_max: int 4775
$ species : chr "Adelie" List of 3
$ body_mass_g_min: int 3950
$ body_mass_g_max: int 6300
$ species : chr "Gentoo" List of 3
$ body_mass_g_min: int 2700
$ body_mass_g_max: int 4800
$ species : chr "Chinstrap"# A tibble: 3 × 3
body_mass_g_min body_mass_g_max species
<int> <int> <chr>
1 2850 4775 Adelie
2 3950 6300 Gentoo
3 2700 4800 ChinstrapWe can agree this presents no danger to dplyr.
In JavaScript, data frames are often arrays of objects (lists); you can use tools like tidyjs:
purrr::keep()), map, reducePlease go to pos.it/conf-workshop-survey.
Your feedback is crucial!
Data from the survey informs curriculum and format decisions for future conf workshops, and we really appreciate you taking the time to provide it.